人工神经网络的基本原理和各种网络结构
什么是人工神经网络
人工神经网络 (ANN) 或模拟神经网络 (SNN),也有人直接用神经网络这个词,它是机器学习的一个重要子领域。深度学习,也可称作深度人工神经网络,是一种具有多层网络结构的人工神经网络。神经网络的基本结构和算法,是深度学习的核心内容。其名称和结构均受到人脑的启发,模拟了人类大脑的部分机理和机制。在这一期,我们将尽可能通俗地向您介绍它的基本原理和目前常见的网络结构,以及他们的使用场景。
基本结构
- 神经元
在神经网络中,最基本的单位就是神经元。它接收来自其他神经元的输入,并通过激活函数来产生输出。

- 输入和权重
每个神经元接收一组输入和一个偏置值,每个输入都带有一个权重,当信号(值)到达时会乘上这个权重,和偏置一起,作为参数传递给激活函数来产生输出。
- 偏置
偏置可以看作是一个模型可以调整的“阈值”,有以下几个作用:
- 提高模型的表达力
- 增加模型的灵活性
- 保证激活函数工作在非线性区域
- 防止模型过拟合
- 激活函数
激活函数的作用就是根据输入和偏置产生输出。针对不同情况,我们可以选择不同的激活函数。使用不同激活函数的主要目的,是增加非线性因素,解决线性模型表达能力不足的缺陷。不同的激活函数,可以让神经元表现出不同的能力,但要注意;每个激活函数有各自的优缺点,有些效果很差,有些需要大量计算。
- 网络层
多个神经元组成网络,这些网络通常具有层级结构。处于同一层的神经元,一般共同完成某个特定的功能。
注意: 在计算层数时,我们通常排除没有计算能力的层。所以一个最简单的单层神经网络,我们只有输出层。
比如:在双层的神经网络中,我们有一个隐藏层,一个输出层。在多层或深度神经网络中,我们有多个隐藏层。一个网络的深度,就是网络的层数。深度学习的名称,就是来源于此。

- 学习过程
神经网络的学习过程可以分为两个阶段:前向传播和反向传播。

- 前向传播
在前向传播中,网络将输入数据通过一系列神经元和权重的计算,得到最终的输出。前向传播,也是神经网络的推理工作过程。
- 反向传播
而在反向传播中,网络通过计算输出与实际标签之间的误差,然后根据误差和所使用的优化算法来调整权重,以减小误差。
重复上面两个步骤,知道误差落在期望的范围内。
注意:反向传播机制 Backpropagation/BP 是整个神经网络最为重要的一个发明,没有反向传播就没有今天的深度学习热潮。人们很早就知道大脑神经元的结构和基本的工作原理,所以我们有了感知机,但是对于大脑神经元是如何学习的,一直没有发现确凿的机制。为了在人工神经网络中解决学习问题,反向传播被好几位人工智能科学家发明出来,并由Geoffrey Hinton等证明了它的有效性,并由此开启了最近十多年的深度学习热潮。
在反向传播中,我们需要知道两个重要的内容: 即损失函数和优化算法。
- 损失函数
在反向传播中,我们使用一个损失函数来衡量网络的预测结果与真实标签之间的差异。像激活函数一样,我们有很多函数可以选择。选择的合理损失函数,精准的描述输出和训练数据之间的相似度,可以让训练过程更有效率,减少迭代次数。
- 优化算法
优化算法则用于更新权重,使得损失函数最小化。我们也发现了一些优化算法,他们各有优缺点。
有了反向传播机制,我们就可以对神经网络进行训练。输入权重和偏置都可以在训练前进行初始化,并通过训练中进行调整。但偏置的调整通常更为关键,且偏置的更新通常不依赖于的输入,它相对独立于当前的网络状态。
小结
了解了上面这些概念,我们知道,构建一个神经网络,我们需要考虑以下一些内容:
- 网络结构,神经元的连接方式和深度
- 神经元的激活函数的选择
- 学习开始前的各种初始化值,尤其是神经元的阈值-偏置
- 学习训练过程中,损失函数和优化算法的选择
知道了这些,你也是一个入门级的人工智能专家了。
常见神经网络结构
接下来我们来介绍一些简单且常见的神经网络结构。这些结构有各自特殊的用途。一个投入应用的神经网络模型,通常由很多这样的简单结构组成。为了便于解说,人们定义了一些常见的网络神经元图标。限于篇幅,我们就不一一介绍。需要指出的是,这里的某些单元,只是内部激活函数不同、某些带自我反馈,还有一些实际是由一组神经元组成,来完成特定的功能。

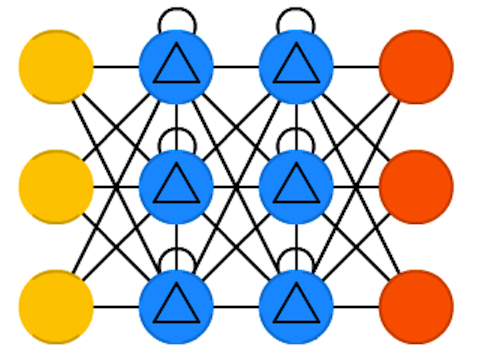
前馈神经网络(FF 或 FFNN)和感知器(P)
前馈神经网络(FF 或 FFNN)和感知器(P)是最直观简单的神经网络,也是我们必须学习的最简单的结构。它们从前端到后端传递信息(分别是输入和输出)。一般来说,两个相邻的层是完全连接的(从一个层的每个神经元到另一个层的每个神经元)。人们通常通过反向传播来训练 FFNN。它们的使用受到很多限制,但它们通常与其他网络结合形成新网络。
感知器由Frank Rosenblatt 在1958年提出。FFNN有一个变种径向基函数 (RBF)网络,是以径向基函数作为激活函数的 FFNN。


循环神经网络 (RNN)
循环神经网络 (RNN)它是带有时间特性的前馈神经网络(FFNN),它们不是无状态的;每个神经元会记住上次的输出,并在新一轮迭代中,作为输入传递给自己。这意味着输入数据的顺序和训练网络的顺序是重要的。RNN面临的一个大问题是梯度消失(或爆炸),这取决于所使用的激活函数,随着时间的推移,信息会迅速丢失。RNN在许多领域都有广泛的应用,包括自然语言处理方面的文本生成、机器翻译、语音识别;时间序列分析方面的股价预测、天气预测;图像描述生成、推荐系统等。 它们的能力在需要考虑时间关系和序列信息的任务中得到充分发挥。
RNN 由 Jeffrey Elman在1990年提出。


长/短期记忆神经网络(LSTM)
长短期记忆网络(LSTM)可以看作是RNN的一种特殊形式,旨在通过引入门和显式定义的记忆单元来解决RNN面临的梯度消失/爆炸问题。这些灵感主要来自电路,而不是生物学。LSTM在每个神经元引入了一个记忆单元和三个门:输入门、输出门和遗忘门。这些门的功能是通过停止或允许信息的流动来保护信息,并在需要时记住或忘记特定的信息。因此,LSTM可以视为对RNN的改进和扩展,能够更有效地处理具有长期依赖性的序列数据。
LSTM 由 Sepp Hochreiter 和 Jürgen Schmidhuber 在1997年提出。



门控循环单元 (GRU)
它是LSTM的一个变体:它们少了一个门,并且接线也略有不同:它们没有输入、输出和忘记门,而是有一个更新门。在某些不需要额外表达能力的情况下,GRU 的性能可以优于 LSTM。
GRU 由郑俊英等人在2014年提出。
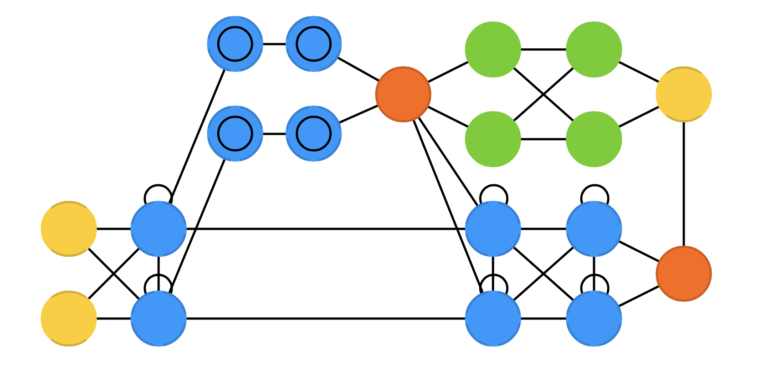
双向循环神经网络、双向长短期记忆网络和双向门控循环单元(分别为 BiRNN、BiLSTM 和 BiGRU)这些都是 RNN,LSTM, GRU的变体。它们的网络结构和对应的网络类似。不同的是,这些网络不仅连接着过去,还连接着未来。举个例子,单向 LSTM 可以通过逐个输入字母来训练来预测单词“fish”,其中随时间变化的循环连接会记住最后一个值。BiLSTM 还将在向后传递时被馈送到序列中的下一个字母,使其能够访问未来的信息。这会训练网络填充间隙而不是推进信息,因此它可以填充图像中间的洞,而不是在边缘扩展图像。
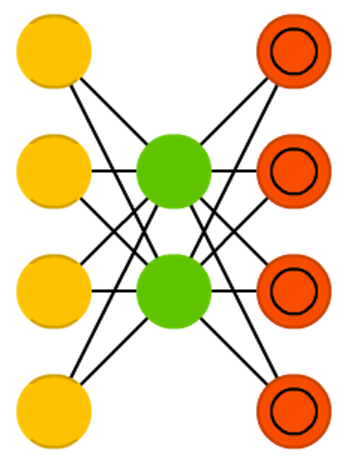
自动编码器 (AE)
自动编码器(AE)是一种用于数据压缩和特征学习的神经网络模型。它在某种程度上类似于前馈神经网络(FFNN),因为自动编码器更像是对FFNN的不同用法,而不是根本上不同的架构。自动编码器的基本思想是自动编码信息(压缩而非加密),因此得名。整个网络始终呈现出沙漏形,中间隐藏层比输入和输出层要小。自动编码器的结构始终围绕中间层对称(根据层数的奇偶性可能有一个或两个中间层)。最小的层几乎总是在中间,这是信息最压缩的地方(网络的瓶颈)。从开始到中间的部分称为编码部分,从中间到结束的部分称为解码部分,中间的部分称为编码。可以通过反向传播来训练它们,通过输入数据并将误差设置为输入与输出之间的差异。在权重方面,自动编码器的构建通常是对称的,因此编码权重与解码权重相同。自动编码器的应用非常广泛,包括图像压缩、信号处理、特征学习、图像去噪等领域。它们也常常被用作其他更复杂模型的预训练步骤,以提高这些模型的性能。
AE 由 Hervé Bourlard 和 Yves Kamp 在 1988年提出
变分自动编码器 (VAE)
变分自动编码器(Variational Autoencoder,简称VAE)是一种生成式模型,是自动编码器(AE)的一种扩展形式。VAE试图学习输入数据的潜在分布,而不仅仅是对输入数据进行重构。它通过学习输入数据的潜在分布,从而可以生成与输入数据类似的新样本。因此它与自动编码器(AE)具有相同的架构,但“教”给它们的东西不同。VAE的优点包括能够生成高质量的样本、具有较好的可解释性和泛化能力等。它在生成式建模、数据压缩、特征学习等领域都有广泛的应用。
VAE 由Diederik P. Kingma 和 Max Welling 在2013年提出

去噪自动编码器 (DAE)
去噪自动编码器 (DAE)是自动编码器(AE)的一个变体,旨在通过学习去除输入数据中的噪声,从而使编码器学习到数据更具鲁棒性的表示。与传统的自动编码器相比,DAE在训练时向输入数据添加噪声,然后尝试将带噪声的输入数据映射回原始的、干净的输入数据。这样一来,编码器必须学习到对输入数据的噪声具有鲁棒性的表示,而解码器则负责恢复原始数据。通过训练去噪自动编码器,可以学习到数据的抽象特征,并且可以在训练过程中对数据进行去噪和降维,从而提高模型对输入数据的表示能力和泛化能力。去噪自动编码器在图像去噪、信号处理、特征学习等领域都有广泛的应用。
DAE 由 Pascal Vincent 等在2008年提出。

稀疏自动编码器 (SAE)
稀疏自动编码器(Sparse Autoencoder,简称SAE)是自动编码器(AE)的一个变体,在某种程度上与 AE 相反。我们不是教网络在更少的“空间”或节点中表示一堆信息,而是尝试在更多的空间中编码信息。其主要目标是通过学习到数据的稀疏表示来提取数据的有效特征。稀疏自动编码器在编码器的隐藏层中引入了稀疏性约束,即限制隐藏单元的激活率,使得只有少数的隐藏单元被激活,大多数则保持不活跃状态。这种稀疏性约束可以通过添加稀疏惩罚项到自动编码器的损失函数中来实现,以鼓励隐藏单元之间的竞争性激活,从而导致只有部分隐藏单元被激活。通过学习到稀疏表示,稀疏自动编码器可以更好地捕获数据的重要特征,并且具有更好的鲁棒性和泛化能力。稀疏自动编码器在特征学习、数据降维和去噪等领域都有广泛的应用。
SAE 由 Marc’Aurelio Ranzato、Christopher Poultney、Sumit Chopra 和 Yann LeCun 在 2007年提出。

马尔可夫链(MC 或离散时间马尔可夫链,DTMC)
马尔可夫链(MC 或离散时间马尔可夫链,DTMC)是 BM 和 HN 的前身。你可以这样理解它们:从我现在所在的这个节点,到我的任何一个邻居节点的几率是多少?它们是无记忆的(即马尔可夫性质),这意味着您最终所处的每个状态完全取决于之前的状态。MC 并不总是被视为神经网络,就像 BM、RBM 和 HN 一样。马尔可夫链也不总是完全连接的。马尔可夫链广泛应用于模拟、随机过程建模、自然语言处理等领域,其简单的数学结构和丰富的理论使其成为研究和应用的重要工具。
MC 由 Brian Hayes 在2013 年提出

Hopfield网络(HN)
Hopfield 网络(Hopfield Network,HN)是一种反馈型神经网络。它是一种全连接的、无层次结构的神经网络模型,用于模拟和存储离散的二值模式。Hopfield 网络的主要特点包括:
- 能量函数:Hopfield 网络使用能量函数来描述系统的状态,并通过最小化能量函数来达到稳定状态。典型的能量函数为霍普菲尔德能量函数,它由网络的连接权重和神经元状态共同决定。
- 自联想记忆:Hopfield 网络具有自联想记忆的能力,即它可以通过学习一组模式来存储这些模式,并在给定部分模式的情况下恢复完整的模式。
- 异联想记忆:除了自联想记忆外,Hopfield 网络还可以通过学习多个模式来进行异联想记忆,即在给定一个模式的情况下,生成与之相关的其他模式。
- 稳定性:Hopfield 网络具有稳定性,即当网络达到一个局部能量最小值时,它将保持在这个状态而不会发生变化。
Hopfield 网络在模式识别、优化、自动关联记忆等领域具有广泛的应用,尤其在解决约束满足问题和解决旅行商问题等组合优化问题方面表现出色。
HN 由 John Hopfield 在1982年提出
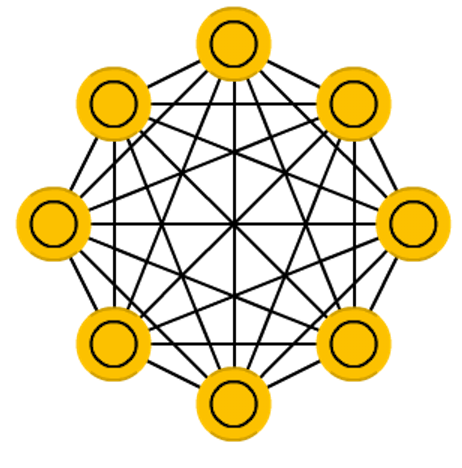

玻尔兹曼机(BM)
玻尔兹曼机(Boltzmann Machine,BM)是一种基于能量的随机生成模型,是一种随机生成的无向图模型,很像 HN,但是:一些神经元被标记为输入神经元,而其他神经元仍然“隐藏”。玻尔兹曼机的主要特点包括:
- 随机性:BM是一种随机生成模型,其中神经元的状态以随机方式更新,从而使得BM具有探索性和随机性,有助于学习数据中的复杂结构和模式。
- 能量函数:BM使用能量函数来描述系统的状态,通常采用伊辛模型的能量函数。该能量函数由网络的连接权重和神经元的状态共同决定。
- Gibbs采样:BM使用Gibbs采样算法进行学习和推断,通过多次迭代更新神经元状态来逼近目标分布。
- 可见层和隐藏层:BM通常包含一个可见层和一个或多个隐藏层,其中可见层用于表示观测数据,隐藏层用于表示潜在特征或抽象表示。
玻尔兹曼机在深度学习和概率建模中具有重要的地位,尤其是在无监督学习和生成模型方面,用于学习和生成概率分布,特别适用于无标签和未标记的数据。它们被广泛应用于降维、特征学习、图像生成、自动编码器等领域,并为深度信念网络(Deep Belief Networks,DBN)等模型的发展奠定了基础。
BM 由Geoffrey Hinton 和 Terry Sejnowski在1985年提出
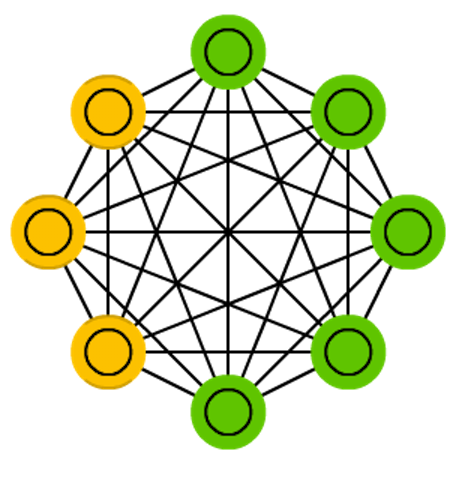


受限玻尔兹曼机 (RBM) 是 玻尔兹曼机(BM)的一个变体。它限制了可见层和隐藏层之间的连接,从而减少了学习和推断的复杂度。
由 Paul Smolensky 在1996年提出
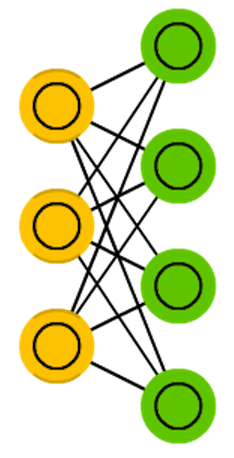
深度置信网络 (DBN)
深度置信网络(Deep Belief Network,DBN)由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)或变分自动编码器 VAE 组成的堆叠结构构成。DBN通常包含一个可见层(输入层)和多个隐藏层,每一层之间是全连接的。DBN的训练过程通常分为两个阶段:预训练和微调。
- 预训练阶段:通过逐层训练受限玻尔兹曼机(RBM),从而逐步初始化整个网络。在这个阶段,每个RBM都被训练来学习数据的分布,并生成对应层的特征表示。
- 微调阶段:通过反向传播算法对整个网络进行微调,以最大化训练数据的似然性。在微调阶段,可以使用梯度下降等优化算法来调整整个网络的参数,从而提高模型的性能。
DBN常用于特征学习和数据生成任务,如图像识别、语音识别、自然语言处理等领域。其深层结构使得DBN能够学习到数据的多层次表示,从而更好地捕捉数据的复杂特征和结构。
DBN 由 约书亚·本吉奥(Yoshua Bengio)等人在2007年提出
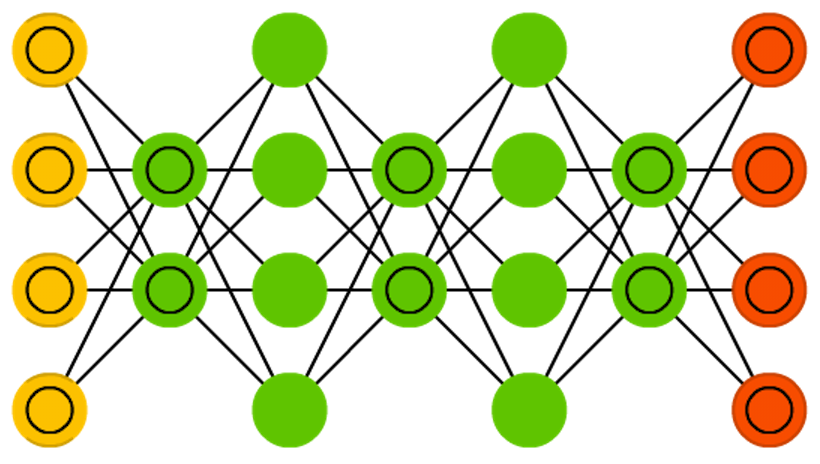

卷积神经网络(CNN 或深度卷积神经网络,DCNN)
CNN 是相对复杂的网络结构,主要由卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)构成。其中,卷积层通过卷积操作提取输入数据的特征,池化层则用于降低特征图的维度,全连接层则负责将特征图映射到输出类别。
注意:
- 卷积层可以有多个卷积核,一个卷积核可被视为一组可学习的参数,或更多地被视为一个特征提取器,而不是一个神经元或一组神经元。
- 池化层由一组池化核构成,池化核不是一组参数或神经元,而是一组固定的操作规则或者模板,用于执行池化操作。
CNN的主要特点包括参数共享、局部感受野和层级结构。参数共享指的是卷积核在不同位置共享参数,从而减少模型的参数量;局部感受野指的是每个卷积核只关注输入数据的局部区域,而不是整个输入数据;层级结构指的是通过堆叠多个卷积层和池化层来逐渐提取输入数据的抽象特征。CNN 的现实世界实现通常将 FFNN 粘合到末尾以进一步处理数据,从而实现高度非线性的抽象。这些网络称为 DCNN,但这两个网络之间的名称和缩写经常互换使用。
CNN在计算机视觉领域取得了巨大成功,广泛应用于图像分类、目标检测、图像分割等任务。其在处理二维结构数据方面的优势使其成为处理图像等任务的首选模型。
由杨乐昆(Yann LeCun)等人于1998年提出。


反卷积网络(DN)
反卷积网络(DN),也称为逆图形网络(IGN),是逆卷积神经网络。反卷积操作通常是通过转置卷积(Transpose Convolution)或分数步长卷积(Fractionally Strided Convolution)来实现的。这些操作允许将特征图的尺寸放大,从而实现从低分辨率到高分辨率的映射。
反卷积网络通常由多个反卷积层、卷积层和池化层组成,其中反卷积层用于上采样,卷积层用于特征提取,池化层用于降低特征图的维度。通过这些层级的组合,反卷积网络可以有效地将低维特征映射回原始高维空间,实现图像重建等任务。
反卷积网络在图像重建、语义分割、图像生成等领域具有广泛的应用,特别是在生成对抗网络(GAN)等模型中扮演着重要的角色。
由 Matthew D Zeiler 等人于2010年提出。

深度卷积逆向图形网络 (DCIGN)
DCIGN在一定程度上可以视为由三个不同的网络组成:它实际上是 VAE,但具有用于各自的编码器和解码器的 CNN 和 DNN。
DCIGN结合了深度卷积神经网络(CNN)和逆向图形学的思想,旨在从输入数据中学习图像的内在表示,并能够对这些表示进行逆向推理,从而生成逼真的图像或理解输入数据的结构和特征。
和VAE类似,DCIGN通常由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责将输入数据(如图像)编码成低维的特征表示,通常使用卷积层和池化层进行特征提取和降维。解码器则将这些特征表示映射回原始的高维数据空间,通过反卷积等操作生成逼真的图像。
DCIGN的训练通常通过最小化重构误差或对抗性损失函数来完成,以使生成的图像与真实图像尽可能接近。通过这种方式,DCIGN能够学习到输入数据的潜在结构和特征,并能够生成与输入数据类似的图像。
DCIGN在图像生成、图像修复、图像超分辨率等任务中具有广泛的应用,同时也为理解图像数据的内在表示提供了有力工具。
由 Tejas D Kulkarni. 等人于2015年提出。

生成对抗网络(GAN)
生成对抗网络(GAN),由两个神经网络组成:生成器和判别器。GAN 由任意两个网络组成,但通常是 FF 和 CNN 的组合,生成器负责生成内容,判别器负责判断内容。这两个网络被训练来相互竞争,以改进其性能。
- 生成器(Generator):生成器尝试从随机噪声中生成逼真的数据样本,例如图像、音频等。它将随机噪声作为输入,并尝试生成与真实数据样本相似的输出。生成器的目标是欺骗判别器,使其无法区分生成的假样本和真实样本。
- 判别器(Discriminator):判别器尝试区分生成器生成的假样本和真实数据样本。它接收来自生成器的样本和真实数据样本,并尝试将它们分类为真实或假的。判别器的目标是准确识别真实数据并拒绝生成的假样本。
GAN的训练过程是一个对抗性的过程:
- 在训练过程中,生成器和判别器交替进行训练。
- 生成器通过生成尽可能逼真的假样本来欺骗判别器。
- 判别器通过尽可能准确地识别真实和假样本来防止被欺骗。
- 这种竞争促使生成器和判别器逐渐提高其性能,最终生成器可以生成逼真的数据样本。
GAN 的训练可能相当困难,因为您不仅需要训练两个网络(其中任何一个都可能带来自己的问题),而且还需要平衡它们的动态。如果预测或生成与另一个相比变得更好,GAN 将不会收敛,因为存在内在分歧。
GAN已被广泛应用于图像生成、风格转换、图像增强、语音合成等领域,并取得了显著的成功。
由 Ian oodfellow 等人于2014年提出。
回声状态网络(ESN)
回声状态网络(Echo State Network,ESN)是一种递归神经网络(RNN)的变体,其设计灵感来源于动态系统理论。ESN的关键思想是在网络内部引入一个大规模的随机循环隐藏层,这个隐藏层被称为“回声状态池”(reservoir),其内部结构是稳定的,且其连接权重是随机初始化的。
在ESN中,输入信号首先经过输入层传递到回声状态池,然后通过输出层产生输出。与传统的RNN不同,ESN的回声状态池一般不进行训练,而是利用随机初始化的连接权重和非线性激活函数,使其在输入信号的驱动下产生动态响应。输出层的权重通常通过简单的线性回归方法进行训练,以将回声状态池中的动态信息映射到所需的输出。
ESN具有很好的非线性动态处理能力和较强的适应性,在时间序列预测、信号处理、模式识别等任务中表现出色。由于其简单、高效的特性,ESN在实际应用中受到了广泛关注,并被用于各种领域的建模和预测任务。
由Herbert Jaeger 和 Harald Haas 于2004年提出。
液态状态机 (LSM)
液态状态机(Liquid State Machine,LSM)的灵感源自于大脑中神经元的工作方式。LSM主要由大量的随机连接和动态状态组成,其中神经元的状态和连接权重在时间上随机变化。它看起来很像 ESN,它们的区别在于:LSM 是一种尖峰神经网络:S 形激活被阈值函数取代,每个神经元也是一个累积记忆单元。
LSM通常用于处理时序数据,如语音识别、运动控制等领域。通过调节LSM中的参数和结构,可以使其适应不同的输入数据和任务要求。LSM已被证明在模式识别和时序预测等任务中具有良好的性能。
由 Wolfgang Maass, Thomas Natschläger 和 Henry Markram 在2002年提出。
极限学习机 (ELM)
极限学习机(Extreme Learning Machine,ELM)是一种单隐层前馈神经网络模型,基本上是 FFNN,但具有随机连接。它们看起来与 LSM 和 ESN 非常相似,但它们不是循环的,也不是尖峰的。他们也不使用反向传播。
其设计旨在实现快速训练和高效的学习。ELM的核心思想是通过随机初始化输入层到隐层之间的连接权重和偏置,然后直接计算输出层到隐层之间的权重,从而加快训练速度。
由于不使用反向传播,ELM的训练过程不需要迭代调整权重和偏置,而是使用解析方法一次性计算输出层的权重。这种直接计算输出权重的方法使得ELM在训练过程中具有非常高的速度,特别适用于大规模数据集和实时应用场景。
ELM主要应用于模式识别、分类和回归等任务,在图像识别、语音处理、生物信息学等领域取得了一定的成功。由于其简单高效的特性,ELM在机器学习和深度学习领域得到了广泛关注和应用。
由 黄广斌等 于 2006年提出。
深度残差网络 (DRN)
深度残差网络 (DRN)是非常深的 FFNN,具有额外的连接,将输入从一层传递到后面的层(通常是 2 到 5 层)以及下一层。其设计灵感来源于残差学习的思想。
在传统的神经网络中,随着网络层数的增加,优化过程变得更加困难,因为深层网络容易出现梯度消失或梯度爆炸的问题。为了解决这个问题,DRN引入了残差块(residual block)的概念。残差块包含了跨层的跳跃连接(skip connection),使得网络可以学习残差函数而不是原始的映射函数。这样一来,即使网络加深,也可以保持良好的梯度流动,从而更容易地训练深层网络。
DRN的优点包括能够训练非常深的网络、提高了梯度的传播效率、减轻了梯度消失问题等。由于其在图像识别、目标检测等任务中取得了很好的效果,DRN已经成为深度学习领域中的经典模型之一。
由 何凯明 等于2015年提出。
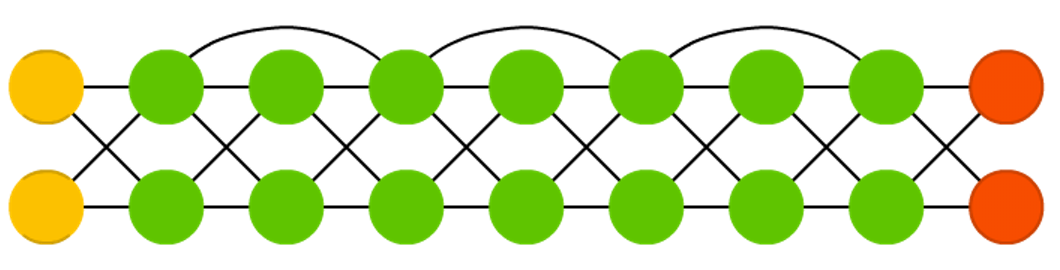
神经图灵机 (NTM)
神经图灵机(Neural Turing Machine,NTM)是一种结合了神经网络和图灵机概念的模型,旨在模拟人类学习和记忆的能力。它可以理解为 LSTM 的抽象,也是一种打破黑盒神经网络的尝试(让我们对其中发生的事情有一些了解)。
NTM具有可读写的外部存储器,使其能够动态地存储和检索信息。这种外部存储器类似于计算机的内存,可以存储大量数据,并且可以通过网络的学习过程进行读写。NTM通过一个控制器(controller)与外部存储器进行交互,控制器可以是循环神经网络(RNN)或长短期记忆网络(LSTM)等。
NTM的工作原理是通过输入数据,控制器读取或写入外部存储器的内容,然后根据读取到的信息进行预测或输出。由于其具有可读写的存储器,NTM能够处理各种复杂的任务,如序列学习、记忆和推理等。
总的来说,NTM结合了神经网络的学习能力和图灵机的通用计算能力,使其在模拟人类智能和解决复杂任务方面具有潜力。
NTM由Alex Graves等人于2014年提出。
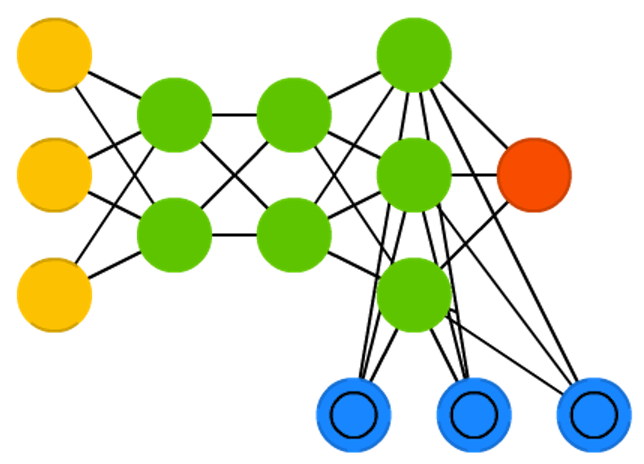
可微神经计算机 (DNC)
可微神经计算机 (DNC)是具有可扩展内存的增强型神经图灵机,其灵感来自于人类海马体存储记忆的方式。DNC旨在模拟人类学习和记忆的能力,并且具有可微分性,使其可以通过梯度下降等优化方法进行训练。与神经图灵机(NTM)类似,DNC也具有可读写的外部存储器,但是在控制器和外部存储器之间添加了可微分的接口,使其能够直接与神经网络结构无缝集成。这种可微分性使得 DNC 可以直接通过反向传播算法进行端到端的训练,而无需额外的训练技巧或算法。
DNC的控制器通常采用循环神经网络(RNN)或长短期记忆网络(LSTM),用于管理和操作外部存储器。控制器通过与外部存储器进行交互,读取、写入和更新存储器中的信息,并根据存储器中的内容进行预测或输出。
总的来说,DNC结合了神经网络的学习能力和外部存储器的记忆能力,并且具有可微分性,使其成为处理复杂任务和模拟人类智能的强大工具。
由Alex Graves等人于2016年提出。

胶囊网络 (CapsNet)
胶囊网络(Capsule Network,CapsNet)是一种受生物学启发的池化替代方案,旨在解决传统卷积神经网络(CNN)在处理姿态变化等复杂空间关系时的局限性。CapsNet中的胶囊(Capsule)是一组嵌入的神经元,但与传统的神经元不同,胶囊内部的神经元被设计成输出一个向量,而不是单个标量值,是对特征的向量化表示,每个胶囊代表一个特定的特征,而不像传统的CNN中使用的神经元。
胶囊网络相比于传统的CNN具有以下几个关键特点:
- 姿态参数化:每个胶囊能够表示特征的存在以及特征的状态,例如其位置、方向等,这使得网络对姿态变化具有更好的适应能力。
- 动态路由:CapsNet中采用了动态路由机制来确定胶囊之间的连接权重,使得网络能够自适应地学习特征之间的关系,从而提高了网络的鲁棒性和泛化能力。
- 层级结构:CapsNet通常由多个胶囊层组成,每个胶囊层可以同时捕捉不同层次的特征表示,从而形成一种层级的特征提取结构。
- 重构损失:CapsNet中引入了重构损失,用于鼓励网络学习对输入数据进行有效的重构,这有助于提高网络对输入数据的表示能力。
总体而言,胶囊网络的提出为解决传统CNN在处理空间关系和姿态变化时的限制提供了一种新的思路和方法,已经在图像识别、语义分割等领域取得了一定的成功。
由 Geoffrey Hinton等人于2017年提出

Kohonen 网络(KN,也称为自组织(特征)图、SOM、SOFM)
Kohonen网络,是一种无监督学习的人工神经网络模型。它利用竞争性学习在没有监督的情况下对数据进行分类。输入被呈现给网络,之后网络评估哪些神经元与该输入最匹配。然后调整这些神经元以更好地匹配输入,并在此过程中拖动它们的邻居。邻居移动的程度取决于邻居到最佳匹配单元的距离。这一过程经过多次迭代后,使得竞争层的神经元在拓扑结构上形成了对输入数据的映射,实现了数据的聚类和可视化。
Kohonen网络在数据挖掘、模式识别、图像处理等领域都有广泛的应用,是一种强大的工具,能够帮助人们理解和处理复杂的数据集。
由芬兰科学家Teuvo Kohonen于1982年提出。

注意力网络(AN)
注意力网络(AN)是一类网络,其中包括 Transformer 架构,旨在模仿人类视觉系统的注意力机制。在传统的神经网络中,每个输入都对输出的影响是相同的,而在注意力网络中,网络可以选择性地关注输入中的某些部分,从而更加灵活地处理输入数据。他们使用注意力机制通过单独存储先前的网络状态并在状态之间切换注意力来对抗信息衰减。编码层中每次迭代的隐藏状态存储在存储单元中。解码层连接到编码层,但它也从经注意力机制上下文过滤的记忆单元接收数据。此过滤步骤为解码层添加了上下文,强调特定特征的重要性。使用来自解码层输出的误差信号来训练产生该上下文的注意力网络。
注意力网络在自然语言处理、计算机视觉和强化学习等领域都有广泛的应用。在自然语言处理中,注意力机制被应用于机器翻译、文本摘要和问答系统等任务中,以提高模型对输入文本的理解能力。目前最火的大语言模型就基于注意力机制。在计算机视觉中,注意力机制被用于目标检测、图像分类和图像生成等任务中,以提高模型对图像内容的关注度和识别能力。在强化学习中,注意力机制被应用于增强智能体对环境的观察和决策过程,以提高智能体的性能和学习效率。
由 Max Jaderberg 等 谷歌研究团队在2015年提出。