人工智能的军备竞赛
最近整个 AI 工业界,消息发布频繁,我感觉像是进入一个军备竞赛阶段,主要竞争集中在大语言模型。我们先来看一下这半年的情况。
先对这个表格做一下说明:
- 高亮的内容,都是外界的猜测,没有获得开发公司的确切数据。
- 红色的条目,都是2024年后发布的模型
- 问号部分,内容未知
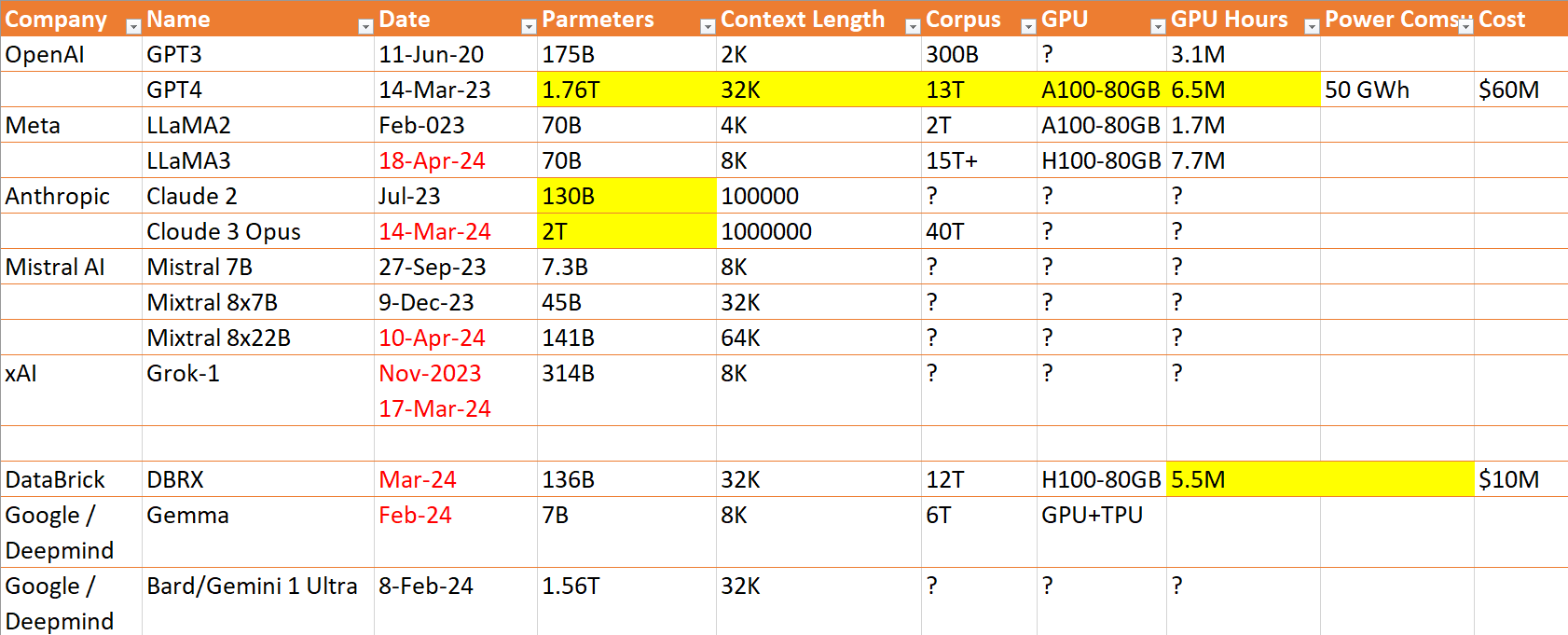
从这个表格里我们看到:
- OpenAI还是行业的标杆,他们在去年3月就把总参数量推到了1.76T,比其他厂商领先一年。如果没有内部宫斗戏,估计新的GPT也已经出来了。即便如此,我还是很期待他们的新模型,尤其期待他们在模型结构上的进步。
- Meta 和 xAI,给我感觉更像一个搅局者。LLaMA3 的口碑还不错,一个小规模的模型,性能不输很多大模型,他们在优化上还是很有一手,我等屌丝玩家还能玩玩。是我个人比较喜欢的模型之一。
- xAI 的 Grok-1,是参数量最大的开源模型。它给我的感觉,纯粹就是Elon不爽 OpenAI 而弄出来恶心他们的,就算是免费的,它至少需要320GB的VRAM来运行 4bits 的模型,如果是 8bits,需要640GB,就算有人送我一堆最顶级的 Nvidia 显卡,我也用不起啊。
- Anthropic 是 AWS 的马甲,Cloude 3 Opus的参数量达到 2T,上下文长度 1 M。
- Mistral 是我比较喜欢的一家法国 AI 初创公司,和 Yann LeCunn和很深的渊源。我个人觉得他们的理念和策略比较合理地考虑了当前的技术水准和商业需求。他们的小模型也调教得非常好,在我常用的模型列表里。
- DataBrick,他们的模型我不熟,估计还是内部使用更多,放出来凑个热闹,增加点知名度。
- 谷歌布局 AI 最早,两个创始人有绝佳的技术头脑,但一路走来,存在感越来越低。这次也不例外,无发可说。题外话,现在有理想、有选择的年轻人都不愿去谷歌,感觉就是个养老的地方。谷歌早晚要搞政治到死。
最后我聊一下对这波AI竞赛的个人看法:
- 最新的商用顶级模型,总参数量都超过1.5T,但即便最大的 2T 参数量,和人类的总突触量相比,还有5000倍的距离。
- 模型的训练成本非常高,高到普通个人,包括研究人员,根本玩不起,这会对技术迭代和进步形成一定的阻碍。
- 堆数据未必是好事,垃圾数据会对模型的效果产生很多负面影响。
- 现在各个厂商都是在堆参数,堆训练数据,模型本身,没有根本性进步。大模型一本正经说瞎话的问题没有根本解决。这种情况下,谁完全信AI,谁倒霉,不要说我言之不预。
对比于简单的提升参数量,添加训练数据,我个人更期待这几个方面:
- 理论上的进步,从数学上获得突破性进展,可以更深入、全面地诠释神经网络的运行机制。
- 新一波的技术进步,出现新的神经网络结构,彻底解决AI幻觉问题。
- 发现并找到合适的运用当前AI技术的方式,这也是最让人感到恐惧但又兴奋的事情。
Category: